MatrixNet. Epic Fail №1 — асессоры.
Асессоры появились в Яндекесе давно. Идея была заимствована у Гугля (наверняка многие из вас слышали, что выдачу в Гугле ранжируют толпы индусов 🙂 ) и сама по себе она была не плохой — с помощью асессора очень удобно отлавливать дорвеи, холвеи, клоаки и прочий SEO-спам, а так же обучать алгоритмы вычислять общие признаки сайтов, не достойных находиться в SERP’е.
Но яндексоиды пошли дальше — они стали с помощью асессоров обучать алгоритмы ранжировать хорошие сайты. Это был Epic Fail №1, сейчас объясню почему.
Широкой публике в деталях работа асессора стала известна с публикацией условий конкурса Интернет-математика 2009. Асессор даёт оценку паре запрос — документ по пятибальной шкале. Кстати, обратите внимание на тотальную невнимательность яндексоидов, что в принципе свойственно талантливым людям: в условиях конкурса оценки от асессоров лежат в диапазоне от 0 до 4, но средняя оценка выдачи победителей — выше 4-х. Чего принципиально быть не может, если только реальная оценка асессоров не лежит в диапазоне от 1 до 5 😉 За год это несоответствие так никто и не заметил.
Итак, у асессора есть 5 оценок. 1 и 2 — это для спама и нерелевантных результатов. 3-ка — это нейтральная оценка — типа слова из запроса в документе присутствуют, но вобще документ не об этом (см. скриншот предудущей заметки — красным обведены именно документы — троечники) 5-ка — суперрелевантный результат, витальный. Чтобы было понятно — по запросу Спорт-Экспресс витальным будет сайт одноимённой газеты. Для всех остальных сайтов — четвёрки.
Вы ещё подвоха не заметили? А зря. Что происходит в результате такой дискретной оценки? Любой коммерческий запрос, не связанный с брендом, не имеет витальных сайтов. Со спамом Яндекс борется хорошо. В итоге, алгоритм обучается ранжировать сайты по коммерческим запросам на одних четвёрках.
Вы скаже ну и чё? (Видимо примерно такие же мысли бродят в голове абстрактного яндексоида). А вот чё.
Во-первых, между двумя соседними целыми числами умещается бесконечное множество чисел рациональных. В переводе на русский это означает, что по любому коммерчески привлекательному запросу найдётся бесконечное множество (если не ограничивать вебмастеров во времени — точно бесконечное 🙂 ) сайтов, оцененных одинаково, но на самом деле достаточно сильно отличающихся своей ценностью для пользователя поисковой системы. То есть, выдача, состоящая из документов соответствующих запросу почти на 5 и выдача, состоящая из документов, соответствующих запросу почти на3 с точки зрения оценивающего качество выдачи алгоритма будут одинаково идеальны, хотя одна из них будет казатся пользователям тихим ужасом.
Именно поэтому Яндекс считает свою выдачу хорошей — ну там же одни четвёрки, не хуже чем в Гугле. Причём ситуация не изменится ровным счётом никак, даже если в реальной жизни Яндекс использует, допустим, десятибальную шкалу оценок.
Потому что, во-вторых, асессор не даёт оценку бизнесу, стоящему за сайтом. Поэтому, что сателлит, не являющийся таковым только по формальным критериям, что лидер в нише, что просто старый заброшенный сайт или сайт-для-бизнеса-на-коленке для асессора, а вместе с ним и для яндекса выглядят одинаково релевантными запросу. Это естественно, потому что асессоры не являются экспертами в оцениваемой ими области.
И чем это нам грозит, спросите вы, ведь даже если сателлиты и заброшенные сайты попадут в топ случайно, то алгоритм дообучится и всё исправит? Беда заключается в том, что асессор-то даст таким сайтам хорошие оценки. А это значит, что алгоритм скорее всего дообучится ещё лучше находить подобные сателлиты и заброшенные сайты, вместо сайтов богатых компаний, вкладывающих деньги в рекламу вообще и в SEO в частности. Что мы и можем наблюдать в выдаче.
Хотите примеров? Их есть у меня. Москва. Запрос мебель для ванной. Первое место сайт http://www.mebel-vanna.ru/:

30-секундный анализ сайта потенциальным покупателем:
1. Логотипа нет
2. Адреса нет
3. Телефон в картинке
Вывод: в лучшем случае это бизнес-на-коленке, в худшем — сателлит, т.к. нормальный сайт телефон в картинку не прячет, нормальный бизнес не боится указать своё физическое месторасположение, а фирма, которая давно существует на рынке обязательно обзаводится логотипом. У каждого из пунктов могут быть исключения, но все вместе они наводят на мысль, что сайт, а точнее бизнес за сайтом — плохонький. А с точки зрения яндекса — он хорошист, а потому всё в порядке.
Я могу привести и ещё примеры. Но, тут случилось забавное совпадение — именно сегодня директор некой инфокомуники лизнул яндекс в попу по самые гланды, озаглавив свой опус так: Яндекс планомерно улучшает контент Рунета. Я не знаю, что это за дядя и что это за компания — видимо несколько отбился от современной SEO-тусовки. Но в статье приводятся цитаты представителей других SEO-компаний из старичков, которые дружно и радостно уверяют нас, как всё в яндексе хорошо, ажно гламурно. Поэтому у меня к вам большая просьба: покажите этим странным дядям и тётям из seo-компаний, а так же яндексоидам (пара-тройка из них точно это сообщение прочитает, а если повезёт, то ссылку скинут и начальству 😉 ), какой трэш иногда присутствует в яндексе на топовых позициях. Лучше — со скриншотами, чтобы было меньше шансов отвертеться 😀 Спасибо!
продожение следует
Такой большой секрет для маленкой такой компании
Идея этой заметки, а точнее даже серии, живёт в моей бедной голове уже почти полгода. В разные периоды времени меня терзало жгучее желание вместо слова секрет написать что-нибудь похлеще, вроде белого пушного полярного зверька:

Имя маленькой такой компании — это Яндекс. Маленькая она хотя бы вот по этой причине:
Ну, это просто так к слову пришлось, хотя по сравнению с Гуглем Яндекс тоже крупным не назовёшь 🙂
Это была преамбула, а теперь собственно амбула aka фабула. Т.е. моя бедная голова, которую разрывает когнитивный диссонанс: глядя на результаты внедрения Матрикснета, я должен предположить, что либо я полный идиот, либо в яндекс понабрали людей, которые мягко говоря в школе и в институте по физике с двойки на тройку перебивались, хотя, возможно, и были отличниками-математиками. И это при том, что априори я считал, что оба утверждения ложны.
До физики мы ещё доберёмся, а сейчас пруфпик, доказывающий, что я нахожусь в здравом уме и твёрдой памяти:
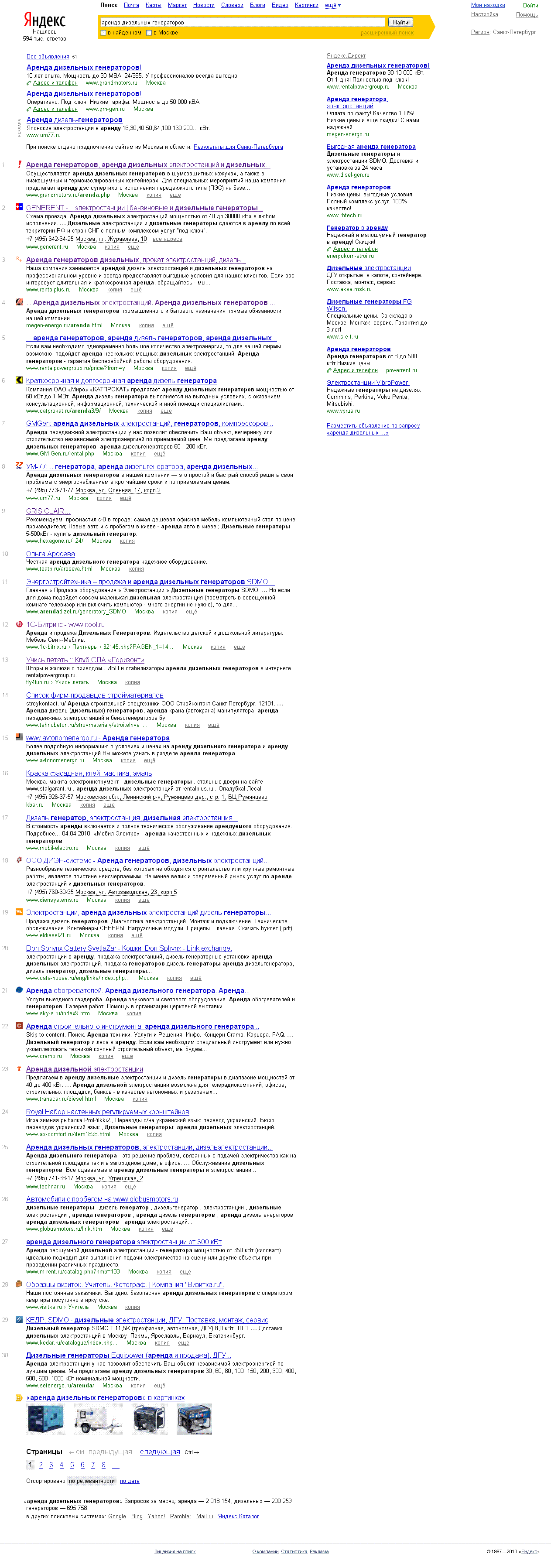{kind=link}
Для тех, кто плохо видит подскажу, что это результаты выдачи по запросу аренда дизельных генераторов для Москвы. В первой тридцатке выдаче 10 сайтов, т.е. ровно треть, не имеют никакого отношения ни к аренде, ни к генераторам, ни к дизельным, а просто содержут SEO ссылки. Я эти сайты на картинке обвёл красным — безобразие начинает твориться с 9-й позиции. Полагаю, что у каждого оптимизатора есть любимый запрос и не один с похожим безобразием.
Я полгода сомневался, как и любой здравомыслящий человек, что другие люди (т.е. яндексоиды) не поголовно глупее меня. Но, поскольку за полгода ситуация не только не улучшилась, но тольку усугубилась, я дозрел до достаточно резких заявлений. Я берусь утверждать, причём не просто утверждать, но и более-менее научно доказать, почему такое безобразие как на приведённой выше картинке, не является случайностью для яндексовских алгоритмов. Более того, я сделаю более сильное утверждение: яндекс не в состоянии отранжировать адекватно пользовательским ожиданиям те запросы, которые не подверглись оценке асессоров и при этом не подверглись влиянию воздейсвтия оптимизаторов. В другой формулировке: без вмешательства человека яндексовские алгоритмы недееспособны.
Прежде чем приступить к доказательствам, которые растянутся на несколько сообщений, предлагаю моим читателям выссказать свои соображения на тему: Почему matrix net полный отстой? 🙂
Яндекс и крокоебалы
Хотел вчера написать пост про крокоебал и караписдиц. Кто такие не спрашивайте, это наверное и первоисточник не знает. Ну, заодно и про Яндекс. Но — заленился. Сегодня Сергей Петренко прямо таки вынудил меня это сделать.
На самом деле, каждый уважающий сеошник должен написать, что они там в Яндексе (Гугле, Рамблере — нужное подчеркнуть) нифига искать не умеют. Конечно, лучше всего писать что они не правильно ищут именно тот сайт, который продвигает оптимизатор, но не все коллеги-конкуренты реагируют на такие сообщения адекватно ожиданиям автора. Поэтому про крокоебал писать политкорректнее.
И так, Яндекс абсолютно точно не умеет находить крокоебал. С учётом того, что он умеет находить караписдиц, можно сделать вывод, что весь поиск у Яндекса работает как-нибудь так (кстати, о принадлежности этой фразе Масяне Яндекс тоже плохо знает). Потому что крокоебалы от караписдиц с точки зрения релевантности ну ни чем не отличаются.
Смайлы приложены в должном количестве.
Тысячи чертей или почему яндексоиды не бреются?
Очень меня напряг "учет нескольких тысяч поисковых параметров для одного документа". Нет, вовсе не как оптимизатора. Как оптимизатору мне достаточно оказывать влияние на 3 параметра документа — относительную частоту запроса в документе, относительную частоту запроса в анкор-листе документа и вес документа, который определяется как сумма передаваемых донорами весов. Этого в принципе достаточно для успешного продвижения.
Меня беспокоят тысячи параметров как немножко программиста и слегка математика.
Начнём с того, что одним из основным принципов программирования (и математики, и философии) является принцип Бритвы Оккама:
entia non sunt multiplicanda praeter necessitatem
(не преумножай сущности без надобности)
Как мне видится, для успешного ранжирования любых документов необходимо и достаточно 4 параметра: к трём вышеупомянутым добавляется возраст документа, и применяется он в случае равенства этих трёх параметров (и для одних типов запросов возраст может идти в плюс, а для других — в минус). А дьявол порылся в точном взвешивании передаваемых ссылками весов: seo-ссылки, естественные ссылки, ссылки с трастовых и ссылки с экспертных документов — все они должны передавать вес по-разному. Ну и ещё разные типы запросов необходимо учится определять, чтобы искать немного по-разному — но это всё не имеет никакого отношения к параметрам самого документа…
Ладно, ладно, я ничерта не понимаю в поиске, а на самом деле, большинство ценных документов располагается на сайтах, сделанных криворукими вебмастерами (был тут недавно в немаленькой такой компании, головной офис которой расположен в Доме Зингера на Невском, так там сайтом рулили 6 вебмастеров, а на подтверждение прав для консоли вебмастера ушло полтора часа) и поэтому на годный документ ведёт единственная ссылка с текстом подробнее с такого же одиноко расположенного документа на богом и Гуглем (но не Яндексом) забытом сайте, а посему для качественного ранжирования столь бесценных для широких масс документов нужны цельных 245 признаков (кстати, кто-нибудь знает, почему 245, а не нормальные для любого программиста 256?). Лично я, как и Петька из анекдота, такое не только написать, но и представить не могу! А теперь заметьте, что всего-то за какие-то полгода количество необходимых для ранжирования параметров вдруг увеличились в 8 (!) раз (минимум в 8, потому что «тысячи» это как минимум две ). Да в ином документе столько букв не бывает сколько придумали параметров яндексоиды.
Хорошо-хорошо, у меня как не у гуманитария очень скудное воображение, поэтому попрошу вообразить вас такую ситуацию: господину Воложу звонит господин Медведев и с чуть меньшим чем у Путина металлом в голосе спрашивает, а почему это по запросу президент выдаётся википедия со статьей не про того президента? Вообразили? А теперь вообразите как яндексоиды будут вспешке определять какой из тысяч параметров подкрутить, чтобы правильный президент в топе был. Вот и у меня не получается. Нет, звонок Медведева Воложу — запросто, а быстрый поиск и исправление ошибки — ну никак.
Гугль, к слову, с задачей выбора правильного президента в вики справляется на раз. Наверное потому, что PageRank вычислять умеет 🙂
Ну и на загрузку опять немножечко математики. Если вам не хватило 1000 параметров, чтобы выбрать и отранжировать первую тысячу документов из всех документов, содержащих слова из запроса пользователя, то вы придумали ровным счётом ничего не значащую тысячу параметров — они совпадают у очень многих документов, а это значит, что «учёт нескольких тысяч поисковых параметров для одного документа» — это не более чем страшная сказка на ночь для ребёнка начинающего сеошника.
Disclaimer: данная заметка ни в коем разе не является попыткой учить кого-либо писать отличный поиск, но является просто выражением удивления, почему Володька не сбрил усы. Правильной бритвой 😀
Upd: комментарий от Ильи Сегаловича.
Это не те «параметры», которые «признаки» или «свойства» (features), а те параметры, из которых строится модель.
Если модель, например, полином второй степени (то есть в качестве параметров используется и признаки и все их произведения) то число параметров модели пропорционально квадрату числа признаков. Чем длиннее модель (чем в ней больше используется параметров) тем точнее можно построить ранжирование или угадать класс объекта или угадать оценку и тп. Однако сложные, длинные модели очень дорого «обсчитывать» по ресурсам.
В этом релизе мы впервые для себя применили очень длинную модель в ранжировании. Для этого пришлось многое переписать.
А признаков у нас, и правда, несколько сотен, и их число и рост их числа, вы совершенно правы, тщательно контролируется и идет конечно же не так быстро.
Дырявый Арзамас
Сегодня ночью надо полагать прошёл полноценный апдейт в Яндексе с новой версией алгоритма — Арзамас 1.1
Как учит теория программирования — нечётные версии содержат большее число ошибок, чем чётные — иногда новая парная ошибка ошибка может улучшать качество программного продукта, о чём открыто пишут и сами яндексоиды. (Некоторые разработчики вообще распространяют только чётные версии, оставляя нечётные для внутреннего использования). Такие ошибки присутствуют в огромных просто количествах и в Арзамасе 1.1. Связаны они с ранжированием некоторых внутренних страниц.
Коротко о предыстории проблемы. Если мне не изменяет мой склероз, примерно в 2006-м году яндексоиды устали бороться с дорвеями. Разрубили гордиев узел они тривиальным способом, дав огромный приоритет главным страницам сайтов (мордам). В итоге доходило до смешного: внутренняя страница сайта, например раздел, посвящённая подробному раскрытию проблемы, содержащая многие естественные (и не только :)) ссылки, проигрывала в выдаче собственной морде, на которой было одно упоминание термина, да и то в ссылке на раздел. И примерно год-полтора после этого Яндекс был поисковиком по мордам.
Ситуация стала меняться в сторону внутренних страниц, начиная с Находки. Сегодня ночью она дошла до абсурда — в региональном (питерском) топе появились абсолютно «нулёвые» страницы — вовсе без внешних ссылок на них. Объединяет их только одно — эти страницы расположены либо на доменах, помещённых в ЯКа, либо на субдоменах, основные домены которых тоже в ЯКе. При этом некоторые из таких внутренних страниц-везунчиков вовсе не переспамлены вхождением термина.
Ушёл ставить эксперименты. С сабдоменами 😉
Яндекс-несходимость
Есть свежий сайт, ещё без региональной привязки. Есть новая внутренняя страница на сайте, без единой внешней ссылки. Страница попала в выдачу сегодня ночью. Т.о. никакой «старой» выдачи нет и быть не может (никаких кэшей пробивать не нужно). Есть 4 взаимодополняющих 2-3—словных низкоконкурентных запроса, по которым проверяются позиции в Яндексе в выдаче для Москвы и Санкт-Петербурга.
В результате имеем следующие позиции: в Москве 4 первых места, а в Санкт-Петербурге только 3 первых места и одно 8-е.
Вывод: поиск Яндекса не гомоморфен. Если проще, то рандомизация выдачи местами присутствует 🙂
Злобный Яндекс
Сайт найден по ссылке. Единственная ссылка, которая обнаруживается в кэше Гугля — с внутренней страницы этого же сайта. В живую на сайте этой ссылки нет. В кэше Яндекса — тоже. Тем не менее Яндекс демонстрирует нам гордое нпс.
Заметают следы?
upd: Как подсказал профессор Селезнёв, всё же были ещё внутряки с такой же ссылкой — не досмотрел. Видимо слишком впечатлился восстанием из пепла ада небытия некоторых снятых ссылок в консоли вебмастера.
Находка: коротко о главном.
О Находке уже писал. Не смотря на то, что я помню про 2-е правило оптимизатора, коротко прокомментирую ранее изложенные пункты.
- Контент рулит. Причём рулит настолько сильно, что одна страница может попадать в топ по куче запросов не имея ни одной входящей ссылки с такими анкорами. Мне по-прежнему это кажется уязвимостью, посмотрим, что на это скажут господа дорвейщики. Эксперименты, само-собой, уже поставлены. Бум ждать.
- Зеркальщика вроде бы настроили, но он тормозит. Упоминаемый косяк с двумя зеркалами в Находке разрешён, но этот блог уже более месяца как переехал (301-м редиректом, вестимо), однако воз и ныне там.
- Слабые ссылки рулят. Тут пока рано говорить гоп, так что ждём-с.
- Внутренние страницы заполоняют топ. Пока доров не особо много вижу, так что это скорее плюс, чем минус.
- Морфология непривычна. Теперь по запросу во множественном числе может выбираться одна страница сайта, а в единственном — другая. Понятно, что это касается не одного сайта, а посему выдача по ранее идентичным запросам теперь существенно различается. Чем-то напоминает гугль до введения рускоязычной морфологии — она была, но достаточно простая. Когда-то мне это нравилось и как пользователю и как оптимизатору. Придётся привыкать заново?
- Косяк с аддитивностью исправлен ещё в Магадане.
- Апдейты происходят практически строго по расписанию. За что отдельное спасибо.
Резюме:жить в Находке можно. Ждём Находку 2.0, а уже потом Анадырь. Полагаю где-то к НГ и 8-му марта соответственно.
P.S: тут кто-то поспешил обозвать меня шоумэном, а блог — транслирующим реалити-шоу. Огорчу, вы обратились не по адресу. Вам — к Константину Эрнсту. Ну или к Радуловой с Паркером. Продолжение БД есс-но будет, но не так сразу — Маузер забраковал уже н-дцатого переводчика, ищу очередного. Видимо в итоге придётся обучаться пользоваться Палкой и делать заявки на мериканских форумах. Плюс к этому магазин надо дозаточить на работу с микронишами, в данной версии он мне уже накачал тьму небриллиантовых браслетов. На что тоже нужно время. К слову, _практически_ заинтересованы в продолжении постов всего три с половиной человека, двое из которых уже догадались получить небольшие советы напрямую. Нетерпение остальных мало понятно — днём позже выйдет продолжение или же раньше — для вас не критично 🙂
P.P.S: предсказанная ревальвация бакса ко всем мировым валютам произошла. Это благотворно сказалось на продажах. Теперь в Штатах должна начаться [внутренняя гипер-] инфляция бакса при сохранении [внешней] ревальвации (баксы со всего мира будут репатриированы в Штаты, т.е. там скоро баксами будут обклеивать стены из-за их избытка, а вне штатов бакс будет восстанавливать утерянный было авторитет из-за недостатка). Штаты в своей истории проделывали подобный трюк не раз (чтобы скостить огромную внутреннюю задолженность и собрать колониальный налог с иностранных капиталов), но всё равно это подобно управляемому сваливанию в штопор на сверхзвуковом истребителе, причём в этот раз самолёт похоже основательно перегружен (долгами; к слову, глядя на табличку по ссылке не могу отделаться от мысли, что если каждый американец набирал кредитов в две руки, то каждый англичанин набирал их в восемь рук). В любом случае турбулентность гарантирована, а посему рекомендуется пристегнуться покрепче и убедиться в наличии парашюта именно под вашим сидением. (Если кто не понял, то сейчас самое время заканчивать раскладку яиц по _разным_ корзинам).
Успехов вам в стрижении капусты!