Мониторинг тенденций дорвеестроительства
Хотите знать, какие методы модны на сегодняшний день у дорвейщиков? Нет ничего проще: заведите блог и нарастите ему PR минимум до 3-х. Дорвейщики сами засветят вам свои методы. И популярные киворды. Разумеется не все (методы и киворды), т.к. далеко не все дорвейщики спамят блоги 🙂
Так, хитом лета было использование возможности одной из популярных CMS размещать для участников свои HTML страницы. Метод убийственный: на старом уважаемом домене появляются новые страницы нужного содержания и запитываются разнообразными ссылками. Был. Метод. Убийственным. Сейчас Гугль вычислил этот метод и вычистил доры такого типа. Как обычно, дорвещиков сгубила жадность: вместо того, чтобы окучивать кучу ниш и выводить по одному дору на запрос, они выводили десятки, если не сотни доров по одному и тому же запросу. В такой ситуации спамрепорт не замедлил себя ждать, после чего доры стали отстреливаться ещё на подлёте.
Оптимизаторский чай
В дни кривых апдейтов я пью оптимизаторский чай:

Рекомендую — после него очень хороший сон. И никаких тревог 🙂
Из «профессиональных» чаёв есть ещё программерский бета-чай. Хотя я немножко программист, но этот чай я пить не рисковал, наверно потому, что хорошо знаю, что такое бета-версия продукта 🙂
Если серьёзно, то кривость апдейта определяется довольно легко: при поиске по точным словосочетаниям Яндекс показывает крайне короткие листинги. В кондиционной тематике, которая по понятным причинам меня интересует довольно сильно, есть один запрос, по которому выдаётся всего 9 сайтов, тогда как в нормальной ситуации таких сайтов больше тысячи. Впрочем, и в других тематиках полных листингов не много. Например, по довольно популярному запросу «пластиковые окна» Яндекс обещает показать более 1700 сайтов, хотя в действительности на данный момент показывает только 35 сайтов:

Так что пьём оптимизаторский чай и ждём корректирующего апдейта.
Допссылки в SERP’е Гугля
Дмитрий Честных вводит в заблуждение своих читателей, отвечая на вопрос как получить допссылки в SERP’е Гугля:
Ответ: Если коротко, то сделать на сайте хорошую навигацию.
Если говорить не коротко, а по существу :), то навигация тут почти не причём. Главным условием наличия допссылок является безоговорочное лидерство по запросу. Например, сайт CNN.com находится на первом месте по запросу news, но допссылки по этому запросу он не имеет. А, например, по запросу CNN они у него есть:
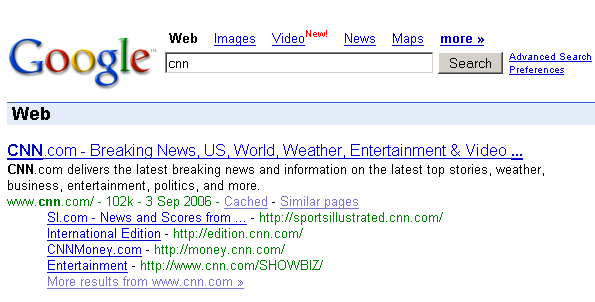
Разумеется, от смены запроса навигация на CNN.com не меняется. Меняется лишь конкурентная среда: по запросу news сайт bbc.co.uk достоин быть первым лишь чуточку меньше.
Первым условием для попадания страницы в допссылки является короткое название ссылки, но не URL. Длинные URL смотрим на картинке, если кто знает длинные названия ссылок — просьба прислать пример.
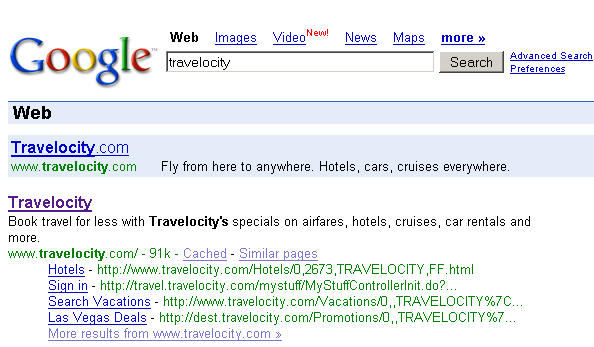
А вторым условием для попадания страницы в допссылки, на мой взгляд, является популярность страницы. Обратите внимание на пример выше: в допссылки не попала страница Flights, но зато попала страница Search Vacations, которая на главной странице есть только в выпадающем JS меню. Нельзя не обратить внимания, что это — первая ссылка в меню, на которую по статистике чаще всего кликают.
Очевидно, что Гугль оценивает популярность страниц не по переходам с поиска, т.к. страница Sign In по определению не может иметь много поискового траффика. И, вероятно, гугль не вычисляет популярность страницы по месторасположению ссылки на эту страницу на морде, т.к. страница Las Vegas Deals из допссылок вообще отсутствует на главной (ссылка с таким текстом на морде есть, но она ведёт на другой поддомен). Т.е. скорее всего используется статистика запросов PageRank для данного URL. Если по простому — данные из тулбара 🙂
Вот такие пироги. Если у кого есть какие-то альтернативные объяснения способа выбора Гуглем страниц для допссылок — не стестняйтесь поделиться соображениями. Приветствуются любые, даже те, которые на первый взгляд кажутся ерундовыми.
Праздник оптимизатора. Подарки от AOL.
Подарком являются данные живых запросов пользователей AOL Search. Вникать в происхождение этих данных мне честно говоря неохота. Брать тут. Я половину уже скачал, через полчаса начну их мучать. Видимо в БД заливка всю ночь производиться будет 🙂
Первые данные по обработке данных — количество кликов в зависимости от позиции:
Results in:
Total Searches:9,038,794
Total Clicks: 4,926,623Click Rank1: 2,075,765
Click Rank2: 586,100 = 3.5x less
Click Rank3: 418,643 = 4.9x less
Click Rank4: 298,532 = 6.9x less
Click Rank5: 242,169 = 8.5x less
Click Rank6: 199,541 = 10.4x less
Click Rank7: 168,080 = 12.3x less
Click Rank8: 148,489 = 14.0x less
Click Rank9: 140,356 = 14.8x less
Click Rank10: 147,551 = 14.1x less
Подтверждено небольшое преимущество 10-го места над 9-м.
А вот на первые три места приходится ок 60% кликов, а не 75-80%, как считали некоторые.
Удачных исследований.
Update:
А вот и информация о происхождении данных:
This collection consists of ~20M web queries collected from ~650k users over three months…
Basic Collection Statistics
Dates:
01 March, 2006 — 31 May, 2006Normalized queries:
36,389,567 lines of data
21,011,340 instances of new queries (w/ or w/o click-through)
7,887,022 requests for «next page» of results
19,442,629 user click-through events
16,946,938 queries w/o user click-through
10,154,742 unique (normalized) queries
657,426 unique user ID’sPlease reference the following publication when using this collection:
G. Pass, A. Chowdhury, C. Torgeson, «A Picture of Search» The First
International Conference on Scalable Information Systems, Hong Kong, June,
2006.
Детская болезнь левизны в Яндексе
Наверное ни для кого не новость, что последние две недели с Яндексом творится что-то неладное. Кое-кто уже строит теорию нового алгоритма. Я же предпочитаю говорить о болезни Яндекса. Смотрите сами. Во-первых, с момента опубликования утилиты мониторинга апдейта не было положенных по расписанию 3-х апдейтов в неделю (соответствующие заявления Ильи Сегаловича заинтересованных отправляю поискать в Яндексе). Во-вторых, Яндекс путается в показаниях.
Вот два скриншота:
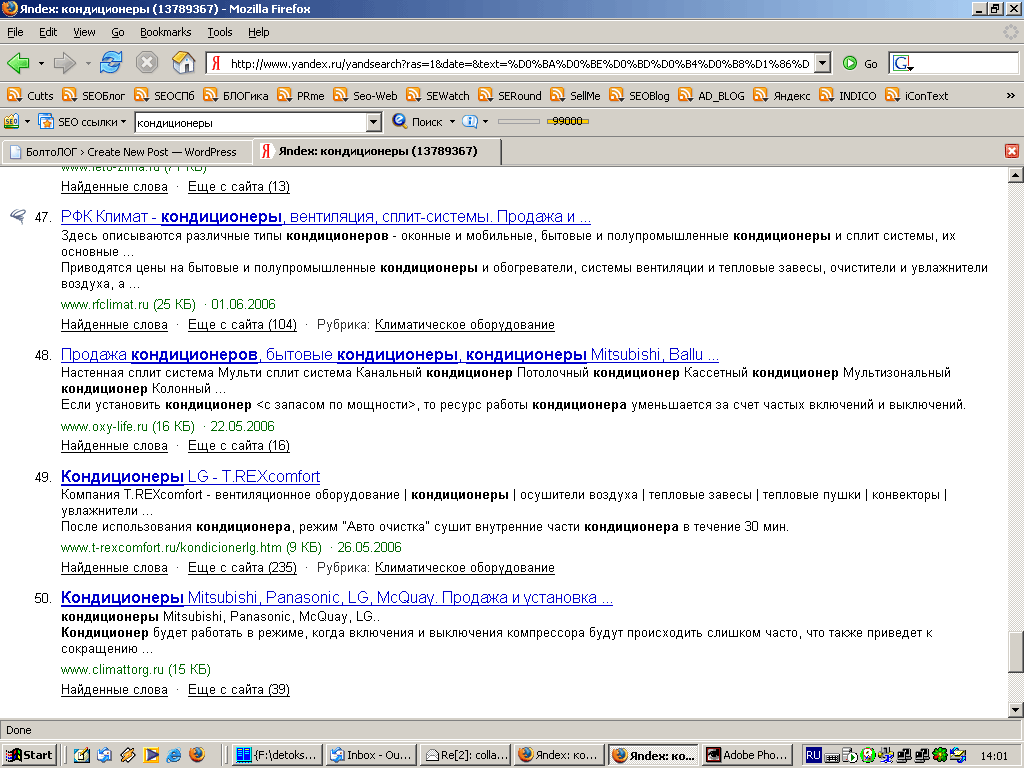
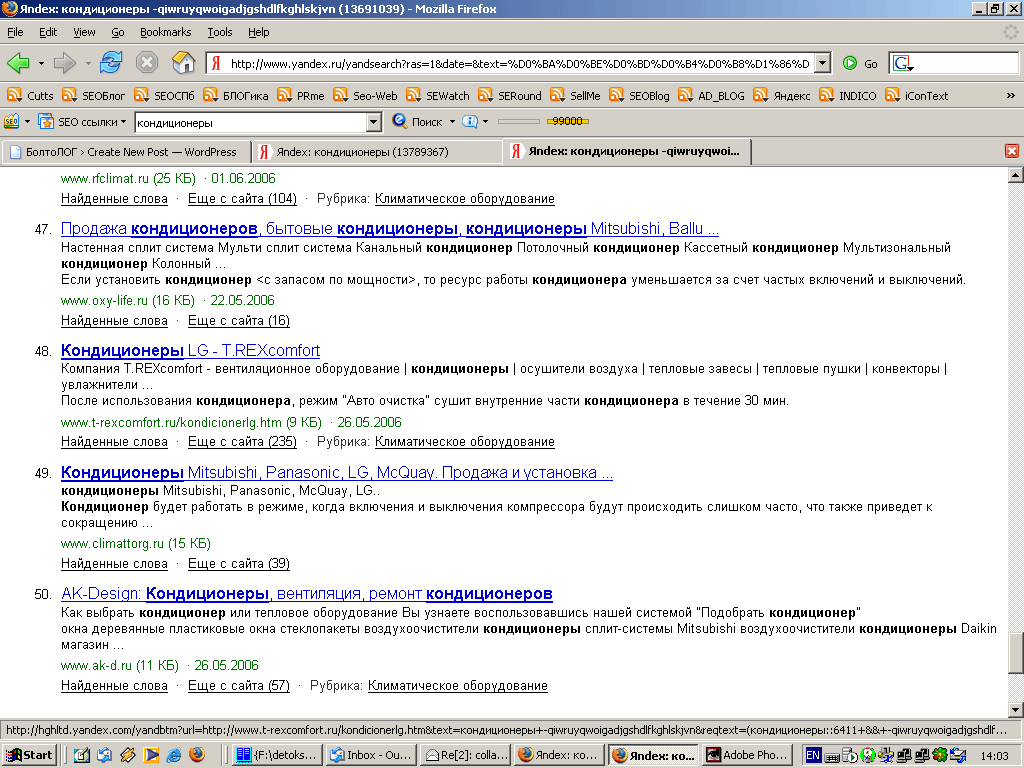
Оба показывают результаты расширенной выдачи по «любимому» запросу кондиционеры. Во втором случае отминусовано несуществующее слово, т.е. запрос выглядит так кондиционеры -qiwruyqwoigadjgshdlfkghlskjvn. Как не трудно видеть, результаты различаются, хотя этого и не должно быть. В чём можно убедиться, проведя аналогичный эксперимент с любым неконкурентным запросом.
Я не буду утверждать, что такие накладки не связаны с изменениями в алгоритме, но мягко намекну, что делать далеко идущие выводы на нестабильной выдаче, мягко, говоря, не дальновидно 🙂 (сам не понял, что сказал :D)
Теперь пару слов о сегодняшнем апдейте, которого не было 🙂 Точнее, его не зафиксировала вышеупомянутая утилитка. То, что происходило ночью очень сильно напоминало положение дел примерно трёхнедельной давности. Продвигаемый сайт по ряду запросов вернулся на первую страницу. Но, больше всего меня радовал «вылетевший» на седьмую страницу запрос. Однако с утра всё вернулось в «поломанное» состояние: по прямому запросу сайт на 7-й странице, а по нему же, но отминусованному несуществующим словом, сайт на первой странице. Так что приходится запасаться терпением и ждать, пока Яндекс избавится от детской болезни левизны и как минимум актуализирует свой кэш.
Новый патент Google на PageRank
Update: первые впечатления. Хорошо заметные ссылки рулят сильнее (проверим), так же рулят интернациональные ссылки (знаем), ссылки с морд (ещё бы), ссылки с обновлённых документов (известно из старого патента).
Во власти ссылок
На днях открыл неприятную для себя особенность Яндекса. Сайт (его морда), продвигающийся по запросам вида товар XX1, товар XX2 и т.д, где XXk -бренд, застрял во втором десятке по некоторым из запросов. Стал изучать причины. Одной из них посчитал слишком далёкое расположение на странице слова товар и некоторых из брендов. Собственно такое упущение было сделано осознанно: бренды перечислялись через запятую, чтобы не писать слышком часто слово товар. Естественно, решил это упущение исправить, cгруппировав бренды на три списка: такие товары XX1, XX2; сякие товары XX3, XX4; разэдакие товары XX5, XX6.
В Гугле это группирование повлекло за собой практически моментальную коррекцию позиций в лучшую сторону от 3-х до 5-ти позиций. В Яндексе же никак не отразилось, даже после второго апдейта.
Выводы: адептом Миныча с его «учением о переколдовщике» мне явно не грозит стать в ближайшее время. А при утверждении «контент рулит» я буду улыбаться во все 32 зуба, если получится конечно 😀 Рулить-то он рулит, да только не в Яндексе.
Ушёл искать новые ссылки.
Любопытный SEO эксперимент
Рекомендую поискать в Г,Р,А и Я точное вхождение фразы «давайте померяемся вицем».
Очень хорошо видны различия алгоритмов:
Гугль считает текст ссылок важным элементом страницы, поэтому сайт-донор находится на первом месте.
Рамблер ссылки не жалует, а потому акцепторы вообще в выдачу не попали. Ссылки же на странице считает менее значимым элементом, чем просто текст, а потому донор поседний.
Апорт вообще на этой фразе спотыкается, и показывает вообще непойми что.
А Яндекс демонстрирует свою любовь к тексту входящих ссылок.